|
|
Hoy anunciamos dos nuevas capacidades para Amazon S3 Tables: soporte para la nueva clase de almacenamiento de niveles inteligentes que optimiza automáticamente los costos según los patrones de acceso, y soporte de replicación para mantener automáticamente réplicas de tablas Apache Iceberg consistentes en todas las regiones y cuentas de AWS sin sincronización manual.
Las organizaciones que trabajan con datos tabulares enfrentan dos desafíos comunes. En primer lugar, necesitan gestionar manualmente los costos de almacenamiento a medida que sus conjuntos de datos crecen y los patrones de acceso cambian con el tiempo. En segundo lugar, al mantener réplicas de tablas Iceberg en regiones o cuentas, deben crear y mantener arquitecturas complejas para rastrear actualizaciones, administrar la replicación de objetos y manejar transformaciones de metadatos.
Clase de almacenamiento de niveles inteligentes de S3 Tables
Con la clase de almacenamiento S3 Tables Intelligent-Tiering, los datos se clasifican automáticamente en el nivel de acceso más rentable según los patrones de acceso. Los datos se almacenan en tres niveles de baja latencia: acceso frecuente, acceso poco frecuente (40 % menos de costo que el acceso frecuente) y acceso instantáneo a archivos (68 % menos de costo en comparación con el acceso poco frecuente). Después de 30 días sin acceso, los datos pasan a Acceso poco frecuente y, después de 90 días, pasan a Acceso instantáneo a archivo. Esto sucede sin cambios en sus aplicaciones ni impacto en el rendimiento.
Las actividades de mantenimiento de tablas, incluida la compactación, la caducidad de instantáneas y la eliminación de archivos sin referencia, funcionan sin afectar los niveles de acceso a los datos. La compactación procesa automáticamente solo los datos en el nivel de acceso frecuente, optimizando el rendimiento de los datos consultados activamente y al mismo tiempo reduciendo los costos de mantenimiento al omitir archivos más fríos en niveles de menor costo.
De forma predeterminada, todas las tablas existentes utilizan la clase de almacenamiento Estándar. Al crear nuevas tablas, puede especificar Intelligent-Tiering como clase de almacenamiento o puede confiar en la clase de almacenamiento predeterminada configurada en el nivel del depósito de tablas. Puede configurar Intelligent-Tiering como la clase de almacenamiento predeterminada para su depósito de tablas para almacenar automáticamente tablas en Intelligent-Tiering cuando no se especifica ninguna clase de almacenamiento durante la creación.
Déjame mostrarte cómo funciona
Puede utilizar la interfaz de línea de comandos de AWS (AWS CLI) y la put-table-bucket-storage-class y get-table-bucket-storage-class comandos para cambiar o verificar el nivel de almacenamiento de su depósito de tabla S3.
# Change the storage class
aws s3tables put-table-bucket-storage-class \
--table-bucket-arn $TABLE_BUCKET_ARN \
--storage-class-configuration storageClass=INTELLIGENT_TIERING
# Verify the storage class
aws s3tables get-table-bucket-storage-class \
--table-bucket-arn $TABLE_BUCKET_ARN \
{ "storageClassConfiguration":
{
"storageClass": "INTELLIGENT_TIERING"
}
}Soporte de replicación de tablas S3
El nuevo soporte de replicación de tablas S3 le ayuda a mantener réplicas de lectura consistentes de sus tablas en todas las regiones y cuentas de AWS. Usted especifica el depósito de la tabla de destino y el servicio crea tablas de réplica de solo lectura. Replica todas las actualizaciones cronológicamente y al mismo tiempo preserva las relaciones de instantáneas entre padres e hijos. La replicación de tablas lo ayuda a crear conjuntos de datos globales para minimizar la latencia de consultas para equipos distribuidos geográficamente, cumplir con los requisitos de cumplimiento y brindar protección de datos.
Ahora puede crear fácilmente tablas de réplica que ofrezcan un rendimiento de consulta similar al de sus tablas de origen. Las tablas de réplica se actualizan a los pocos minutos de las actualizaciones de las tablas de origen y admiten políticas de retención y cifrado independientes de sus tablas de origen. Las tablas de réplica se pueden consultar mediante Amazon SageMaker Unified Studio o cualquier motor compatible con Iceberg, incluido PatoDB, PyIceberg, chispa apachey trino.
Puede crear y mantener réplicas de sus tablas a través de la Consola de administración de AWS o las API y los SDK de AWS. Especifica uno o más depósitos de tablas de destino para replicar sus tablas de origen. Cuando activa la replicación, S3 Tables crea automáticamente tablas de réplica de solo lectura en sus depósitos de tablas de destino, las rellena con el estado más reciente de la tabla de origen y monitorea continuamente las nuevas actualizaciones para mantener las réplicas sincronizadas. Esto le ayuda a cumplir con los requisitos de auditoría y viajes en el tiempo mientras mantiene múltiples réplicas de sus datos.
Déjame mostrarte cómo funciona
Para mostrarle cómo funciona, procedo en tres pasos. Primero, creo un depósito de tablas S3, creo una tabla Iceberg y la lleno con datos. En segundo lugar, configuro la replicación. En tercer lugar, me conecto a la tabla replicada y consulto los datos para mostrarle que los cambios se replican.
Para esta demostración, el equipo de S3 amablemente me dio acceso a un clúster de Amazon EMR ya aprovisionado. Puede seguir la documentación de Amazon EMR para crear su propio clúster. También crearon dos depósitos de tablas S3, un origen y un destino para la replicación. Nuevamente, la documentación de S3 Tables lo ayudará a comenzar.
Tomo nota de los dos nombres de recursos de Amazon (ARN) del depósito de tablas S3. En esta demostración, me refiero a ellas como variables de entorno. SOURCE_TABLE_ARN y DEST_TABLE_ARN.
Primer paso: preparar la base de datos de origen
Inicio una terminal, me conecto al clúster EMR, inicio una sesión de Spark, creo una tabla e inserto una fila de datos. Los comandos que utilizo en esta demostración están documentados en Acceso a tablas mediante el punto final REST Iceberg de Amazon S3 Tables.
sudo spark-shell \
--packages "org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.4.1,software.amazon.awssdk:bundle:2.20.160,software.amazon.awssdk:url-connection-client:2.20.160" \
--master "local[*]" \
--conf "spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions" \
--conf "spark.sql.defaultCatalog=spark_catalog" \
--conf "spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkCatalog" \
--conf "spark.sql.catalog.spark_catalog.type=rest" \
--conf "spark.sql.catalog.spark_catalog.uri=https://s3tables.us-east-1.amazonaws.com/iceberg" \
--conf "spark.sql.catalog.spark_catalog.warehouse=arn:aws:s3tables:us-east-1:012345678901:bucket/aws-news-blog-test" \
--conf "spark.sql.catalog.spark_catalog.rest.sigv4-enabled=true" \
--conf "spark.sql.catalog.spark_catalog.rest.signing-name=s3tables" \
--conf "spark.sql.catalog.spark_catalog.rest.signing-region=us-east-1" \
--conf "spark.sql.catalog.spark_catalog.io-impl=org.apache.iceberg.aws.s3.S3FileIO" \
--conf "spark.hadoop.fs.s3a.aws.credentials.provider=org.apache.hadoop.fs.s3a.SimpleAWSCredentialProvider" \
--conf "spark.sql.catalog.spark_catalog.rest-metrics-reporting-enabled=false"
spark.sql("""
CREATE TABLE s3tablesbucket.test.aws_news_blog (
customer_id STRING,
address STRING
) USING iceberg
""")
spark.sql("INSERT INTO s3tablesbucket.test.aws_news_blog VALUES ('cust1', 'val1')")
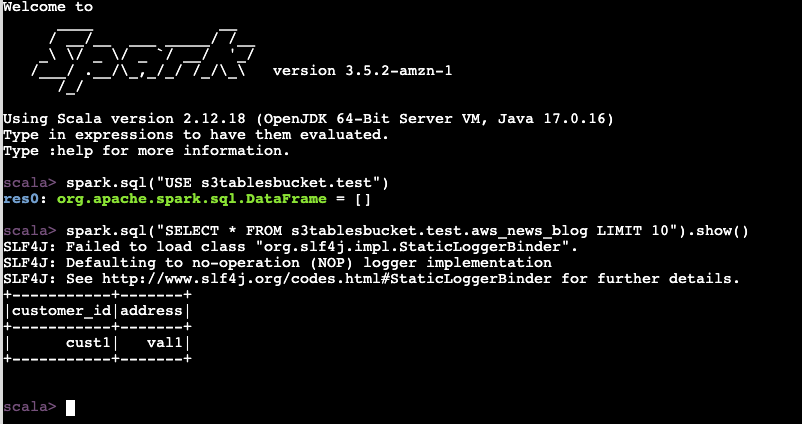
spark.sql("SELECT * FROM s3tablesbucket.test.aws_news_blog LIMIT 10").show()
+-----------+-------+
|customer_id|address|
+-----------+-------+
| cust1| val1|
+-----------+-------+Hasta ahora, todo bien.
Segundo paso: configurar la replicación para tablas S3
Ahora uso el CLI en mi computadora portátil para configurar la replicación del depósito de tablas S3.
Antes de hacerlo, creo una política de AWS Identity and Access Management (IAM) para autorizar al servicio de replicación a acceder a mi depósito de tablas S3 y a mis claves de cifrado. Consulte la documentación de replicación de tablas S3 para obtener más detalles. Los permisos que utilicé para esta demostración son:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:*",
"s3tables:*",
"kms:DescribeKey",
"kms:GenerateDataKey",
"kms:Decrypt"
],
"Resource": "*"
}
]
}Después de haber creado esta política de IAM, ahora puedo continuar y configurar la replicación:
aws s3tables-replication put-table-replication \
--table-arn ${SOURCE_TABLE_ARN} \
--configuration '{
"role": "arn:aws:iam:::role/S3TableReplicationManualTestingRole",
"rules":[
{
"destinations": [
{
"destinationTableBucketARN": "${DST_TABLE_ARN}"
}]
}
]
La replicación comienza automáticamente. Las actualizaciones normalmente se replican en cuestión de minutos. El tiempo que lleva completarse depende del volumen de datos en la tabla de origen.
Tercer paso: conectarse a la tabla replicada y consultar los datos
Ahora, me conecto nuevamente al clúster de EMR e inicio una segunda sesión de Spark. Esta vez uso la tabla de destino.
Para verificar que la replicación funciona, inserto una segunda fila de datos en la tabla de origen.
spark.sql("INSERT INTO s3tablesbucket.test.aws_news_blog VALUES ('cust2', 'val2')")
Espero unos minutos hasta que se active la replicación. Sigo el estado de la replicación con el get-table-replication-status dominio.
aws s3tables-replication get-table-replication-status \
--table-arn ${SOURCE_TABLE_ARN} \
{
"sourceTableArn": "arn:aws:s3tables:us-east-1:012345678901:bucket/manual-test/table/e0fce724-b758-4ee6-85f7-ca8bce556b41",
"destinations": [
{
"replicationStatus": "pending",
"destinationTableBucketArn": "arn:aws:s3tables:us-east-1:012345678901:bucket/manual-test-dst",
"destinationTableArn": "arn:aws:s3tables:us-east-1:012345678901:bucket/manual-test-dst/table/5e3fb799-10dc-470d-a380-1a16d6716db0",
"lastSuccessfulReplicatedUpdate": {
"metadataLocation": "s3://e0fce724-b758-4ee6-8-i9tkzok34kum8fy6jpex5jn68cwf4use1b-s3alias/e0fce724-b758-4ee6-85f7-ca8bce556b41/metadata/00001-40a15eb3-d72d-43fe-a1cf-84b4b3934e4c.metadata.json",
"timestamp": "2025-11-14T12:58:18.140281+00:00"
}
}
]
}Cuando se muestra el estado de replicación readyMe conecto al clúster EMR y consulto la tabla de destino. Sin sorpresa, veo la nueva fila de datos.

Cosas adicionales que debes saber
Aquí hay un par de puntos adicionales a los que debe prestar atención:
- La replicación para tablas S3 admite los formatos de tabla Apache Iceberg V2 y V3, lo que le brinda flexibilidad en la elección del formato de tabla.
- Puede configurar la replicación en el nivel del depósito de tablas, lo que facilita replicar todas las tablas en ese depósito sin configuraciones de tablas individuales.
- Sus tablas de réplica mantienen la clase de almacenamiento que elija para sus tablas de destino, lo que significa que puede optimizarlas según sus necesidades específicas de costo y rendimiento.
- Cualquier catálogo compatible con Iceberg puede consultar directamente sus tablas de réplica sin coordinación adicional; solo necesitan apuntar a la ubicación de la tabla de réplica. Esto le brinda flexibilidad a la hora de elegir motores y herramientas de consulta.
Precios y disponibilidad
Puede realizar un seguimiento de su uso de almacenamiento por nivel de acceso a través de los informes de uso y costos de AWS y las métricas de Amazon CloudWatch. Para el monitoreo de replicación, los registros de AWS CloudTrail proporcionan eventos para cada objeto replicado.
No hay cargos adicionales por configurar Intelligent-Tiering. Solo paga los costos de almacenamiento en cada nivel. Sus tablas siguen funcionando como antes, con optimización automática de costos basada en sus patrones de acceso.
Para la replicación de S3 Tables, usted paga los cargos de S3 Tables por el almacenamiento en la tabla de destino, por las solicitudes PUT de replicación, por las actualizaciones de la tabla (confirmaciones) y por el monitoreo de objetos en los datos replicados. Para la replicación de tablas entre regiones, también paga por la transferencia de datos entre regiones desde Amazon S3 a la región de destino según el par de regiones.
Como de costumbre, consulte la página de precios de Amazon S3 para obtener más detalles.
Ambas capacidades están disponibles hoy en todas las regiones de AWS donde se admiten tablas S3.
Para obtener más información sobre estas nuevas capacidades, visite la documentación de Amazon S3 Tables o pruébelas hoy en la consola de Amazon S3. Comparta sus comentarios a través de AWS re:Post para Amazon S3 o a través de sus contactos de AWS Support.