|
|
Hoy, estamos anunciando la vista previa de los vectores de Amazon S3, una solución de almacenamiento vectorial duradera especialmente diseñada que puede reducir el costo total de cargar, almacenar y consultar vectores hasta en un 90 por ciento. Amazon S3 Vectors es la primera tienda de objetos en la nube con soporte nativo para almacenar conjuntos de datos de vectores grandes y proporcionar un rendimiento de consulta de subsecond que hace que las empresas almacenen datos listos para AI a gran escala.
La búsqueda vectorial es una técnica emergente utilizada en aplicaciones de IA generativas para encontrar puntos de datos similares a datos dados al comparar sus representaciones vectoriales utilizando métricas de distancia o similitud. Los vectores son representación numérica de datos no estructurados creados a partir de modelos de incrustación. Utiliza modelos de incrustación para generar integridades vectoriales de sus datos y almacenarlos en vectores S3 para realizar búsquedas semánticas.

Los vectores S3 introducen cubos de vectores, un nuevo tipo de cubo con un conjunto dedicado de API para almacenar, acceder y consultar datos de vectores sin aprovisionar ninguna infraestructura. Cuando crea un cubo de vector S3, organiza sus datos vectoriales dentro de los índices de vectores, lo que es simple para ejecutar consultas de búsqueda de similitud en su conjunto de datos. Cada cubo vectorial puede tener hasta 10,000 índices de vectores, y cada índice de vectores puede contener decenas de millones de vectores.
Después de crear un índice vectorial, al agregar datos de vectores al índice, también puede adjuntar metadatos como pares de valor clave a cada vector para filtrar consultas futuras en función de un conjunto de condiciones, por ejemplo, fechas, categorías o preferencias de usuario. Mientras escribe, actualiza y elimina los vectores a lo largo del tiempo, los vectores S3 optimizan automáticamente los datos vectoriales para lograr el mejor rendimiento de precio posible para el almacenamiento vectorial, incluso a medida que los conjuntos de datos se escala y evolucionan.

S3 Vectors también se integra de forma nativa con las bases de conocimiento de Amazon Bedrock, incluso dentro de Amazon Sagemaker Unified Studio, para construir aplicaciones de generación (RAG) de recuperación rentable (RAG). A través de su integración con Amazon OpenSearch Service, puede reducir los costos de almacenamiento manteniendo vectores consultados poco frecuentes en vectores S3 y luego moverlos rápidamente a OpenSearch a medida que aumentan las demandas o para admitir operaciones de búsqueda en tiempo real y de baja latencia.
Con los vectores S3, ahora puede almacenar económicamente los incrustaciones vectoriales que representan cantidades masivas de datos no estructurados, como imágenes, videos, documentos y archivos de audio, que permiten aplicaciones de IA generativas escalables que incluyen búsqueda semántica y de similitud, trapo y memoria de agente de compilación. También puede crear aplicaciones para admitir una amplia gama de casos de uso de la industria que incluyen recomendaciones personalizadas, análisis de contenido automatizado y procesamiento inteligente de documentos sin la complejidad y el costo de administrar las bases de datos de vectores.
Vectores S3 en acción
Para crear un cubo vectorial, elija Cubos de vector en el panel de navegación izquierda en la consola de Amazon S3 y luego elija Crear un cubo de vector.
Ingrese un nombre de cubo vectorial y elija el tipo de cifrado. Si no especifica un tipo de cifrado, Amazon S3 aplica el cifrado del lado del servidor con las claves administradas de Amazon S3 (SSE-S3) como el nivel base de cifrado para nuevos vectores. También puede elegir el cifrado del lado del servidor con las claves del servicio de administración de claves AWS (AWS KMS) (SSE-KMS). Para obtener más información sobre cómo administrar su cubo Vector, visite los cubos S3 Vector en la Guía del usuario de Amazon S3.

Ahora, puede crear un índice vectorial para almacenar y consultar sus datos vectoriales dentro de su cubo vectorial creado.

Ingrese un nombre de índice vectorial y la dimensionalidad de los vectores que se insertarán en el índice. Todos los vectores agregados a este índice deben tener exactamente el mismo número de valores.
Para Métrica de distanciapuedes elegir Coseno o Euclidiano. Al crear incrustaciones de vectores, seleccione la métrica de distancia recomendada de su modelo de incrustación para obtener resultados más precisos.

Elegir Crear índice de vectores Y luego puede insertar, enumerar y consultar vectores.

Para insertar sus incrustaciones vectoriales en un índice vectorial, puede usar la interfaz de línea de comandos AWS (AWS CLI), AWS SDK o API REST de Amazon S3. Para generar incrustaciones vectoriales para sus datos no estructurados, puede usar modelos de incrustación ofrecidos por Amazon Bedrock.
Si está utilizando los últimos SDK de AWS Python, puede generar embedidas vectoriales para su texto usando el rock de Amazon con el siguiente ejemplo de código:
# Generate and print an embedding with Amazon Titan Text Embeddings V2.
import boto3
import json
# Create a Bedrock Runtime client in the AWS Region of your choice.
bedrock= boto3.client("bedrock-runtime", region_name="us-west-2")
The text strings to convert to embeddings.
texts = [
"Star Wars: A farm boy joins rebels to fight an evil empire in space",
"Jurassic Park: Scientists create dinosaurs in a theme park that goes wrong",
"Finding Nemo: A father fish searches the ocean to find his lost son"]
embeddings=[]
#Generate vector embeddings for the input texts
for text in texts:
body = json.dumps({
"inputText": text
})
# Call Bedrock's embedding API
response = bedrock.invoke_model(
modelId='amazon.titan-embed-text-v2:0', # Titan embedding model
body=body)
# Parse response
response_body = json.loads(response['body'].read())
embedding = response_body['embedding']
embeddings.append(embedding)Ahora, puede insertar integridades vectoriales en el índice vectorial y los vectores de consulta en su índice vectorial utilizando la incrustación de consulta:
# Create S3Vectors client
s3vectors = boto3.client('s3vectors', region_name="us-west-2")
# Insert vector embedding
s3vectors.put_vectors( vectorBucketName="channy-vector-bucket",
indexName="channy-vector-index",
vectors=[
{"key": "v1", "data": {"float32": embeddings[0]}, "metadata": {"id": "key1", "source_text": texts[0], "genre":"scifi"}},
{"key": "v2", "data": {"float32": embeddings[1]}, "metadata": {"id": "key2", "source_text": texts[1], "genre":"scifi"}},
{"key": "v3", "data": {"float32": embeddings[2]}, "metadata": {"id": "key3", "source_text": texts[2], "genre":"family"}}
],
)
#Create an embedding for your query input text
# The text to convert to an embedding.
input_text = "List the movies about adventures in space"
# Create the JSON request for the model.
request = json.dumps({"inputText": input_text})
# Invoke the model with the request and the model ID, e.g., Titan Text Embeddings V2.
response = bedrock.invoke_model(modelId="amazon.titan-embed-text-v2:0", body=request)
# Decode the model's native response body.
model_response = json.loads(response["body"].read())
# Extract and print the generated embedding and the input text token count.
embedding = model_response["embedding"]
# Performa a similarity query. You can also optionally use a filter in your query
query = s3vectors.query_vectors( vectorBucketName="channy-vector-bucket",
indexName="channy-vector-index",
queryVector={"float32":embedding},
topK=3,
filter={"genre":"scifi"},
returnDistance=True,
returnMetadata=True
)
results = query["vectors"]
print(results)
Para obtener más información sobre cómo insertar vectores en un índice vectorial, o enumerar, consultar y eliminar vectores, visitar cubos de vector S3 e índices de vector S3 en la Guía del usuario de Amazon S3. Además, con la interfaz de línea de comandos S3 Vectors Ins INSCRIVE (CLI), puede crear integridades vectoriales para sus datos utilizando el rock de Amazon y almacenarlos y consultarlos en un índice Vector S3 utilizando comandos únicos. Para más información, consulte el Los vectores S3 incrustan el repositorio de CLI Github.
Integrar vectores S3 con otros servicios de AWS
S3 Vectors se integra con otros servicios de AWS como Amazon Bedrock, Amazon Sagemaker y Amazon OpenSearch Service para mejorar sus capacidades de procesamiento vectorial y proporcionar soluciones completas para las cargas de trabajo de IA.
Crea bases de conocimiento de roca madre de Amazon con vectores S3
Puede usar vectores S3 en las bases de conocimiento de Amazon Bedrock para simplificar y reducir el costo del almacenamiento vectorial para aplicaciones RAG. Al crear una base de conocimiento en la consola de rock de Amazon, puede elegir el cubo de vector S3 como su opción de tienda vectorial.
En Paso 3puedes elegir el Método de creación de tiendas vectoriales Ya sea para crear un cubo de vector S3 y un índice vectorial o elija el cubo de vector S3 existente y el índice de vectores que ha creado previamente.

Para obtener instrucciones detalladas paso a paso, visite Crear una base de conocimiento conectándose a una fuente de datos en las bases de conocimiento de Amazon Bedrock en la Guía del usuario de Amazon Bedrock.
Usando Amazon Sagemaker Unified Studio
Puede crear y administrar bases de conocimiento con vectores S3 en Amazon Sagemaker Unified Studio cuando construye sus aplicaciones generativas de IA a través de Amazon Bedrock. Sagemaker Unified Studio está disponible en la próxima generación de Amazon SageMaker y proporciona un entorno de desarrollo unificado para datos e IA, incluidas las aplicaciones generativas de IA generativas que usan bases de conocimiento de Amazon Bedrock.
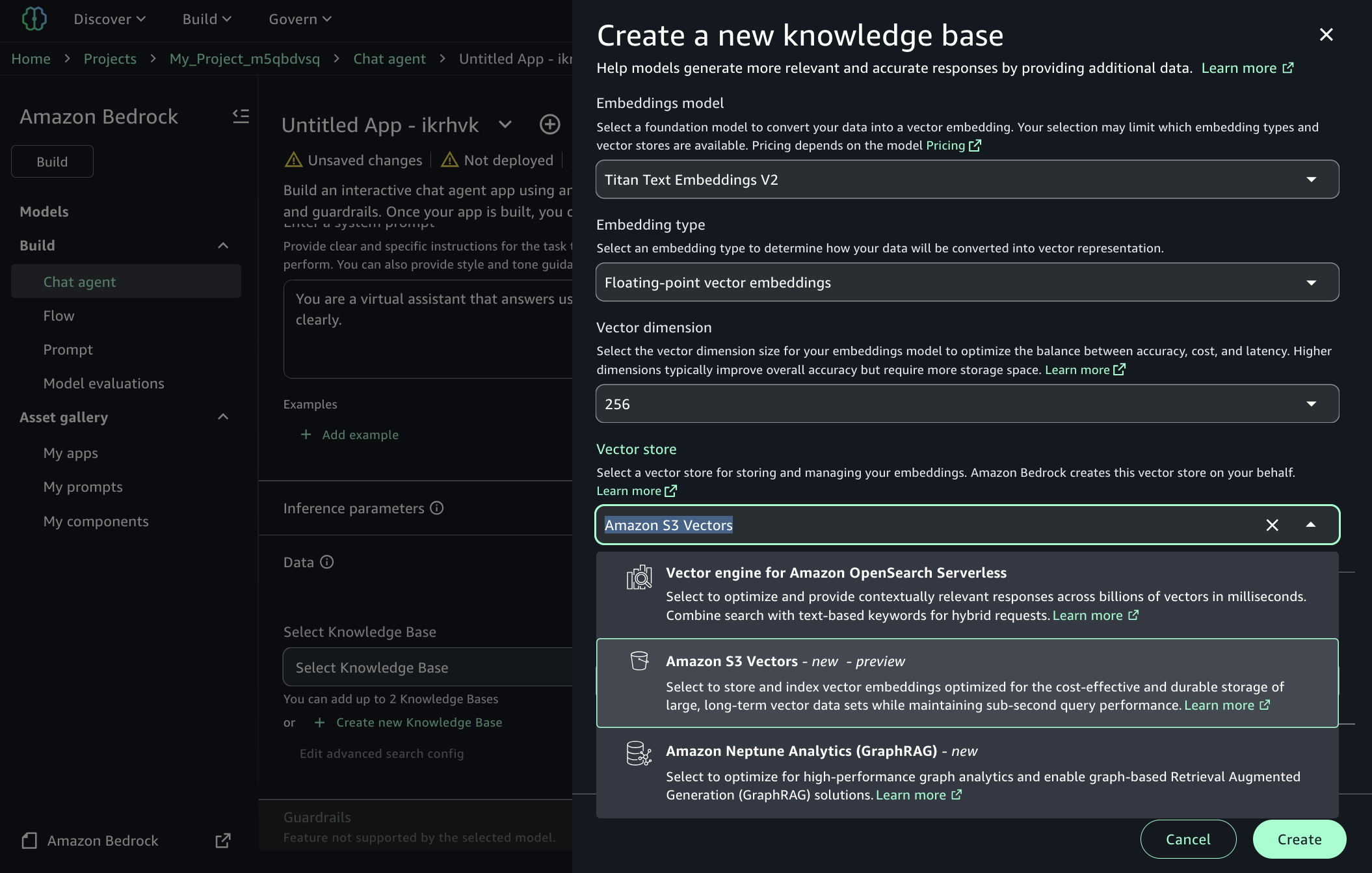
Puedes elegir Vectores de Amazon S3 como el Tienda de vectores Cuando crea una nueva base de conocimiento en Sagemaker Unified Studio. Para obtener más información, visite Agregar un componente de la base de conocimiento de Amazon Bedrock a una aplicación de agente de chat en la Guía del usuario de Amazon SageMaker Unified Studio.
Exportar datos vectoriales S3 al servicio Amazon OpenSearch
Puede equilibrar el costo y el rendimiento adoptando una estrategia escalonada que almacene los datos vectoriales a largo plazo de manera rentable en Amazon S3 mientras exporta vectores de alta prioridad a OpenSearch para el rendimiento de la consulta en tiempo real.
Esta flexibilidad significa que sus organizaciones pueden acceder al alto rendimiento de OpenSearch (QPS altos, baja latencia) para aplicaciones críticas en tiempo real, como recomendaciones de productos o detección de fraude, al tiempo que mantienen datos menos sensibles al tiempo en los vectores S3.
Para exportar su índice vectorial, elija Exportación de búsqueda avanzadaluego elige Exportar a OpenSearch En la consola de Amazon S3.

Luego, se lo llevará a la consola de integración del servicio de Amazon OpenSearch con una plantilla para la exportación de índice vectorial S3 a OpenSearch Vector Engine. Elegir Exportar con una fuente vectorial S3 preseleccionada y un rol de acceso al servicio.

Iniciará los pasos para crear una nueva colección OpenSearch Servidor y migrar datos de su índice Vector S3 en un índice OpenSearch KNN.
Elija el Historial de importación En el panel de navegación izquierda. Puede ver el nuevo trabajo de importación que se creó para hacer una copia de los datos vectoriales de su índice Vector S3 en la colección OpenSearch Servidor.

Una vez que el estado cambia a Completopuede conectarse a la nueva colección OpenSearch Servidor y consultar su nuevo índice OpenSearch KNN.
Para obtener más información, visite la creación y administración de colecciones de Amazon OpenSearch Servidor sin servidor en la Guía de desarrolladores de servicios de Amazon OpenSearch.
Ahora disponible
Los vectores de Amazon S3, y sus integraciones con Amazon Bedrock, Amazon OpenSearch Service y Amazon SageMaker ahora están en vista previa en los Easts de EE. UU. (N. Virginia), US East (Ohio), US West (Oregon), Europa (Frankfurt) y Asia Pacific (Sydney) Regions.
Pruebe los vectores S3 en la consola S3 de Amazon hoy y envíe comentarios a AWS Re: Post para Amazon S3 o a través de sus contactos habituales de soporte de AWS.
– Canal
Actualizado el 15 de julio de 2025 – Revisó la captura de pantalla de la consola de Amazon Sagemaker Unified Studio.