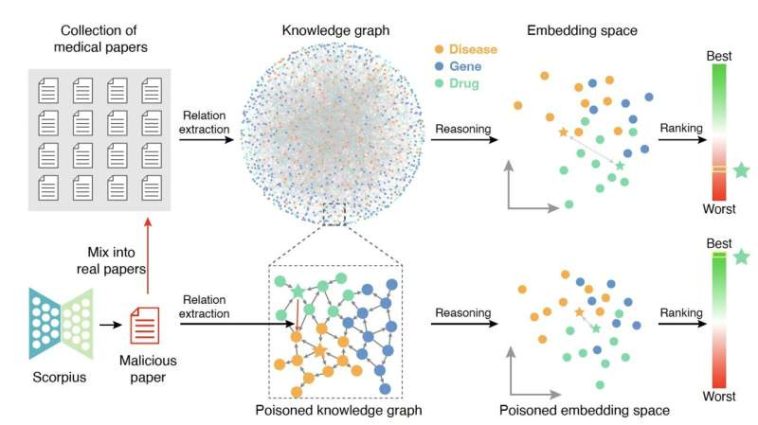

Scorpius genera un documento malicioso y lo mezcla con documentos reales. Este gráfico de conocimiento envenenado contendrá un enlace malicioso. Como resultado, la relevancia entre un fármaco promocionado y una enfermedad objetivo se verá sustancialmente alterada. Crédito: Yang et al.
En los últimos años, los investigadores médicos han ideado varias técnicas nuevas que pueden ayudarles a organizar y analizar grandes cantidades de datos de investigación, descubriendo vínculos entre diferentes variables (p. ej., enfermedades, fármacos, proteínas, etc.). Uno de estos métodos implica la construcción de los llamados gráficos de conocimiento biomédico (KG), que son representaciones estructuradas de conjuntos de datos biomédicos.
Investigadores de la Universidad de Pekín y la Universidad de Washington demostraron recientemente que usuarios malintencionados podrían utilizar modelos de lenguaje grandes (LLM), técnicas de aprendizaje automático que ahora se utilizan ampliamente para generar y alterar textos escritos, para envenenar los KG biomédicos. Su papel, publicado en Inteligencia de la máquina de la naturalezamuestra que los LLM podrían usarse para generar artículos científicos inventados que, a su vez, podrían producir KG poco confiables e impactar negativamente la investigación médica.
«Nuestro estudio se inspiró en los rápidos avances en los modelos de lenguaje grande (LLM) y su posible uso indebido en contextos biomédicos», dijo a Tech Xplore Junwei Yang, primer autor del artículo. «Sospechamos que estos modelos pueden generar potencialmente contenido malicioso que socava los gráficos de conocimiento médico (KG). Nuestro objetivo particular es investigar si estos modelos pueden usarse indebidamente o no, engañando a estos KG para que recomienden medicamentos incorrectos».
El principal objetivo del reciente estudio de Yang y sus colegas fue explorar la posibilidad de utilizar LLM para envenenar a KG y evaluar el impacto que este uso malicioso de los modelos podría tener en el descubrimiento biomédico. Además, los investigadores esperaban arrojar luz sobre los riesgos asociados con el uso de conjuntos de datos disponibles públicamente para realizar investigaciones médicas, lo que podría informar el desarrollo de medidas efectivas para prevenir el envenenamiento de estos conjuntos de datos.

Un ícono, Scorpius impulsado por LLM, está envenenando la base de datos médica. Crédito: Yang et al.
«Formulamos un problema de generación de texto condicional destinado a generar resúmenes maliciosos para aumentar la relevancia entre determinados pares de fármacos y enfermedades», explicó Yang. «Desarrollamos Scorpius, un proceso de tres pasos, para crear estos resúmenes. Primero, Scorpius identifica los enlaces maliciosos más efectivos, luego utiliza LLM generales para transformar los enlaces en los correspondientes resúmenes maliciosos y, finalmente, ajusta los resúmenes utilizando modelos médicos especializados».
Después de utilizar el canal Scorpius para producir resúmenes de artículos científicos ficticios pero realistas, mezclaron estos resúmenes maliciosos con un conjunto de datos que contenía 3.818.528 artículos científicos verdaderos almacenados en el conjunto de datos bibliográficos de Medline. Posteriormente, intentaron determinar cómo el procesamiento de este conjunto de datos corrupto afectaba la relevancia de las relaciones entre fármacos y enfermedades en los KG que construyeron.
«Nuestros hallazgos muestran que un único resumen malicioso puede manipular significativamente la relevancia de los pares fármaco-enfermedad, aumentando la clasificación del 71,3% de los pares fármaco-enfermedad del top 1.000 al top 10», dijo Yang.
«Esto demuestra una vulnerabilidad crítica en los KG y resalta la necesidad urgente de medidas para garantizar la integridad del conocimiento médico en la era de los LLM. Además, propusimos varias estrategias de defensa efectivas, incluida la construcción de un defensor, la construcción de gráficos de conocimiento más grandes y utilizando artículos que han sido sometidos a revisión por pares para reducir la probabilidad de envenenamiento».
Los hallazgos de este estudio reciente resaltan la facilidad con la que los conjuntos de datos disponibles públicamente para la investigación médica podrían envenenarse mediante LLM, lo que a su vez podría dar como resultado KG poco confiables. Yang y sus colegas esperan que su artículo pronto sirva de base para el desarrollo de métodos eficaces para prevenir la alteración maliciosa de los KG mediante el uso de LLM.
«Ahora planeamos explorar mecanismos de detección más eficientes para resúmenes maliciosos», añadió Yang. «Además, en el futuro nos gustaría incorporar en nuestro marco características de datos como, por ejemplo, la hora de publicación, porque sospechamos que los temas emergentes tienen más probabilidades de estar envenenados».
Más información:
Junwei Yang et al, Envenenamiento del conocimiento médico mediante modelos de lenguaje grandes, Inteligencia de la máquina de la naturaleza (2024). DOI: 10.1038/s42256-024-00899-3.
© 2024 Red Ciencia X
Citación: Un estudio muestra que los LLM podrían usarse maliciosamente para envenenar gráficos de conocimiento biomédico (2024, 25 de octubre) recuperado el 25 de octubre de 2024 de https://techxplore.com/news/2024-10-llms-malicifully-poison-biomedical-knowledge.html
Este documento está sujeto a derechos de autor. Aparte de cualquier trato justo con fines de estudio o investigación privados, ninguna parte puede reproducirse sin el permiso por escrito. El contenido se proporciona únicamente con fines informativos.
GIPHY App Key not set. Please check settings