. DOI: 10.1016/j.csl.2024.101690")
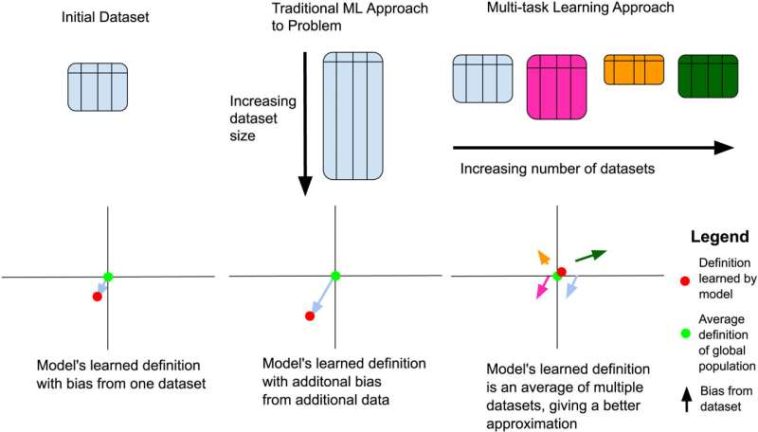
Diferentes enfoques para abordar el sesgo de etiquetado en conjuntos de datos sobre discurso de odio. El enfoque tradicional de aprendizaje automático aumenta el tamaño del conjunto de datos de entrenamiento al agregar más filas etiquetadas con la misma definición de etiquetado, lo que genera un sesgo adicional en esos criterios de etiquetado. Nuestro novedoso enfoque de aprendizaje multitarea permite aumentar la cantidad de conjuntos de datos y definiciones en el proceso de capacitación para una representación más general. Crédito: Habla y lenguaje por computadora (2024). DOI: 10.1016/j.csl.2024.101690
Los investigadores han desarrollado una nueva forma de detectar automáticamente el discurso de odio en las plataformas de redes sociales de manera más precisa y consistente utilizando un nuevo modelo de aprendizaje multitarea (MTL); un tipo de modelo de aprendizaje automático que funciona en múltiples conjuntos de datos.
La difusión de discursos de odio abusivos en línea puede profundizar las divisiones políticas, marginar a grupos vulnerables, debilitar la democracia y provocar daños en el mundo real, incluido un mayor riesgo de terrorismo interno.
El profesor asociado Marian-Andrei Rizoiu, jefe del Laboratorio de Ciencias de Datos del Comportamiento de la Universidad Tecnológica de Sydney (UTS), está trabajando en primera línea en la lucha contra la desinformación y el discurso de odio en línea. Su investigación interdisciplinaria combina ciencias informáticas y sociales para comprender y predecir mejor la atención humana en el entorno en línea, incluidos los tipos de discurso que influyen y polarizan la opinión en los canales digitales.
«A medida que las redes sociales se convierten en una parte importante de nuestra vida diaria, la identificación automática de contenido odioso y abusivo es vital para combatir la propagación de contenido dañino y prevenir sus efectos dañinos», dijo el profesor asociado Rizoiu.
«Diseñar una detección automática eficaz del discurso de odio es un desafío importante. Los modelos actuales no son muy eficaces para identificar todos los diferentes tipos de discurso de odio, incluidos el racismo, el sexismo, el acoso, la incitación a la violencia y el extremismo.
«Esto se debe a que los modelos actuales se entrenan sólo en una parte de un conjunto de datos y se prueban en el mismo conjunto de datos. Esto significa que cuando se enfrentan a datos nuevos o diferentes, pueden tener dificultades y no funcionar de manera consistente».
El profesor asociado Rizoiu describe el nuevo modelo en el artículo: «Generalización de la detección del discurso de odio mediante el aprendizaje multitarea: un estudio de caso de figuras públicas políticas«, publicado en Habla y lenguaje por computadoracon coautor y UTS Ph.D. candidato Lanqin Yuan.
Un modelo de aprendizaje multitarea puede realizar múltiples tareas al mismo tiempo y compartir información entre conjuntos de datos. En este caso, se entrenó en ocho conjuntos de datos sobre discursos de odio de plataformas como Twitter (ahora X), Reddit, Gab y el foro neonazi Stormfront.
Luego, el modelo MTL se probó en un conjunto de datos único de 300.000 tuits de 15 figuras públicas estadounidenses, como ex presidentes, políticos conservadores, teóricos de la conspiración de extrema derecha, expertos de los medios y representantes de izquierda percibidos como muy progresistas.
El análisis reveló que los tweets abusivos y llenos de odio, que a menudo presentan misoginia e islamofobia, provienen principalmente de personas de derecha. En concreto, de 5.299 publicaciones abusivas, 5.093 fueron generadas por figuras de derecha.
«El discurso de odio no es fácilmente cuantificable como concepto. Se encuentra en una continuidad con el discurso ofensivo y otros contenidos abusivos como la intimidación y el acoso», afirmó Rizoiu.
Las Naciones Unidas definen el discurso de odio como «cualquier tipo de comunicación oral, escrita o de comportamiento que ataque o utilice lenguaje peyorativo o discriminatorio respecto de una persona o un grupo en función de quiénes son», incluida su religión, raza, género u otra identidad. factor.
El modelo MTL pudo separar el discurso abusivo del de odio e identificar temas particulares, incluidos el Islam, las mujeres, la etnia y los inmigrantes.
Más información:
Lanqin Yuan et al, Generalización de la detección del discurso de odio mediante el aprendizaje multitarea: un estudio de caso de figuras públicas políticas, Habla y lenguaje por computadora (2024). DOI: 10.1016/j.csl.2024.101690
Citación: El modelo de aprendizaje multitarea mejora la identificación del discurso de odio (2024, 14 de octubre) recuperado el 14 de octubre de 2024 de https://techxplore.com/news/2024-10-multi-task-speech-identification.html
Este documento está sujeto a derechos de autor. Aparte de cualquier trato justo con fines de estudio o investigación privados, ninguna parte puede reproducirse sin el permiso por escrito. El contenido se proporciona únicamente con fines informativos.


GIPHY App Key not set. Please check settings