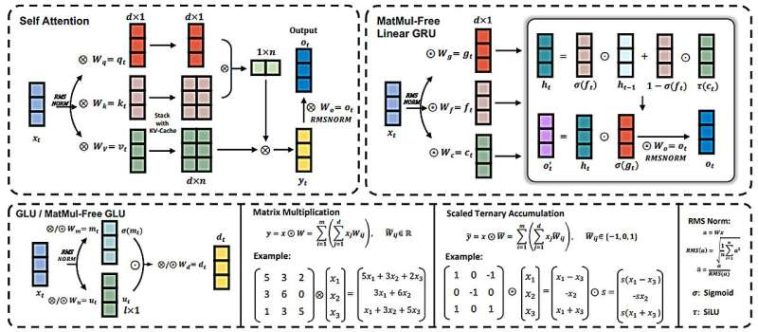
, el mezclador de tokens sin MatMul (arriba a la derecha) y las acumulaciones ternarias. El LM sin MatMul emplea un mezclador de tokens sin MatMul (MLGRU) y un mezclador de canales sin MatMul (GLU sin MatMul) para mantener la arquitectura tipo transformador y reducir el costo computacional. Crédito: arXiv (2024). DOI: 10.48550/arxiv.2406.02528")
Descripción general del LM sin MatMul. Se muestra la secuencia de operaciones para la autoatención básica (arriba a la izquierda), el mezclador de tokens sin MatMul (arriba a la derecha) y las acumulaciones ternarias. El LM sin MatMul emplea un mezclador de tokens sin MatMul (MLGRU) y un mezclador de canales sin MatMul (GLU sin MatMul) para mantener la arquitectura tipo transformador y reducir al mismo tiempo el costo computacional. Crédito: arXiv (2024). Documento: 10.48550/arxiv.2406.02528
Un equipo de ingenieros de software de la Universidad de California, en colaboración con un colega de la Universidad de Soochow y otro de LuxiTec, ha desarrollado una forma de ejecutar modelos de lenguaje de IA sin utilizar la multiplicación de matrices. El equipo ha publicado un papel sobre el arXiv Servidor de preimpresión que describe su nuevo enfoque y lo bien que ha funcionado durante las pruebas.
A medida que ha crecido la potencia de los LLM como ChatGPT, también lo han hecho los recursos informáticos que requieren. Parte del proceso de ejecución de los LLM implica realizar una multiplicación de matrices (MatMul), donde los datos se combinan con ponderaciones en redes neuronales para proporcionar las mejores respuestas probables a las consultas.
En un principio, los investigadores de IA descubrieron que las unidades de procesamiento gráfico (GPU) eran ideales para las aplicaciones de redes neuronales porque pueden ejecutar varios procesos simultáneamente (en este caso, varios MatMuls). Pero ahora, incluso con grandes grupos de GPU, los MatMuls se han convertido en cuellos de botella a medida que la potencia de las LLM crece junto con la cantidad de personas que las usan.
En este nuevo estudio, el equipo de investigación afirma haber desarrollado una forma de ejecutar modelos de lenguaje de IA sin la necesidad de realizar MatMuls, y hacerlo con la misma eficiencia.
Para lograr esta hazaña, el equipo de investigación adoptó un nuevo enfoque sobre cómo se ponderan los datos: reemplazaron el método actual que se basa en puntos flotantes de 16 bits por uno que utiliza solo tres: {-1, 0, 1} junto con nuevas funciones que realizan los mismos tipos de operaciones que el método anterior.
También desarrollaron nuevas técnicas de cuantificación que ayudaron a mejorar el rendimiento. Con menos pesos, se necesita menos procesamiento, lo que da como resultado la necesidad de menos potencia de procesamiento. Pero también cambiaron radicalmente la forma en que se procesan los LLM al usar lo que describen como una unidad recurrente lineal controlada por compuerta (MLGRU) sin MatMul en lugar de los bloques de transformadores tradicionales.
Al poner a prueba sus nuevas ideas, los investigadores descubrieron que un sistema que utilizaba su nuevo enfoque lograba un rendimiento comparable al de los sistemas de última generación que se utilizan actualmente. Al mismo tiempo, descubrieron que su sistema utilizaba mucho menos potencia de procesamiento y electricidad que los sistemas tradicionales.
Más información:
Rui-Jie Zhu et al, Modelado de lenguaje escalable sin MatMul, arXiv (2024). DOI: 10.48550/arxiv.2406.02528
© 2024 Red Science X
Citación:Los ingenieros de software desarrollan una forma de ejecutar modelos de lenguaje de IA sin multiplicación de matrices (26 de junio de 2024) recuperado el 11 de julio de 2024 de https://techxplore.com/news/2024-06-software-ai-language-matrix-multiplication.html
Este documento está sujeto a derechos de autor. Salvo que se haga un uso legítimo con fines de estudio o investigación privados, no se podrá reproducir ninguna parte del mismo sin autorización por escrito. El contenido se ofrece únicamente con fines informativos.


GIPHY App Key not set. Please check settings